agentic ai - observability 360
agentic ai observability key usecases and definite need guide
agents
Any new technology, architecture, tools, frameworks evolves, initially it will be lagging of security and observability. If you are an old software engineer, you could realize this very well like API security, DevSecOps, Secret manager, Centralized logging and monitoring, Anomaly detection, UEBA, SAST ..etc are were grown or built later of certain architecture evolvement such that distributed architecture (Microservice), Cloud Native Application Architecture, Cloud infrastructure. On the same line now Generative AI architecture, Agentic ai architecture.
Having said, many industries are started to adopt the agentic ai and generative ai architecture and exploring applicable business use cases. Also made huge investments on this space.
Does Security and Observability is covered completely for these new architectures? Certainly not. Still there are some level of improvements are happening but not completely enterprise ready. Security and Observability First strategy should mandate as like Design Frist approach.
The observability platform must be ready for the Application Architects or engineers to start design and develop their agents. The current Enterprise observability platforms must be ready to adopt and support new architectures - agentic ai . Unfortunately it is not so easy as like the transformation from monolithic to non-monolithic (Microservice) architecture, On-Premises to cloud transformations. Agentic-ai it is a completely all together new software evaluation.r text here...
Agents are everywhere!
Agents are everywhere across all the phases of SDLC
Agents and Human - transforming your business idea /use case in to specification document.
Human - Architect and solutioning agentic ai, tool selection, workflow design
Agents and Human - Cloud /Co-Piolet/Gemeni ai / Open API to build the software / tool/ application
Agents - test your software / tool/ application
Agents - Perform DevOps
Agents - Productionizing you application
Agents - Serving user request by performing reasoning, thinking, analyzing, tool calling, share memory data, collaborate w agents and continuous autonomous task
The above list of process step depicts the simplest agentic ai - SDLC .ere...
Death of 200 ok.
Agentic ai - involves branching, non-deterministic Execution Tree, and single user request turns the agentic ai flows such that planning, memory retrievals, tool routing, and cross-agent handoffs. Tracking what happened by tracing the agentic flow is not only satisfy and there is must need to be analyze why the agents made such decision? Hallucination score? State transition ? Cost per unit of work? Agents life state monitoring such that bort/live/operate/destroyed (since most of the time agents will be created as new and perform some task and destroyed once its job done which are short lived agents)? Standardizing prompt/tool/datasource versioning, monitoring, Semantic Conventions (SemConv) for all tracing/span .
It is mandatory that agentic ai architecture that demands the new set of observability usecases which can be extended by the current observability platforms and bring the new observable solution by leveraging current observability tools / frameworks /products.
What happened vs Why it so?
Write your Most standard success code we worked so far is HTTP status code 200 ok. REST APIs are the most standard and common practice to interface to your application program. Agents are also invoked or triggered using api approach. Assuming there is a response from agent for the user request which is not appropriate for the specific use case nevertheless the status code will still shows 200 ok which is wrong same case is true especially when agent is hallucinate. Hence trusting 200 ok as always is not a good strategy as like APM(Application programming monitoring).text here...
Traditional Observability
CPU, Memory, API Latency, HTTP Error Codes, transactional flow
LLM Monitoring (Basic GenAI)
Agentic Observability
Prompt/Response pairs, Token Costs, Hallucination scores.
CPU, Memory, API Latency, HTTP Error Codes, transactional flow
Agents, What if ?
Failed to while performing task in the middle
Long waiting agent - dependent agent taking long time or infinite LLM calls
failed to capture agents inappropriate decisions defined by Guardrail -
failure of dynamic prompt generated by another agent in the workflow pipeline
Versioning - un managed version of model/prompt /tool/ triggers Hallucination of agents response in spite of agent perform good .
Failed while collaborating multiple agents
exchanges Sensitive data between other agents
illegal attempt to invoke agent or agents state data Access control of agents -
Failure on Classification of prompt
infinite loop of retry or invoke
Failure of dynamic agent workflow designed by agent itself - most of the case agent will define the work flow and prompt by itself based on the user query and available tool/prompt - this work flow is invisible and un managed traceability.
Behaviour is anomaly
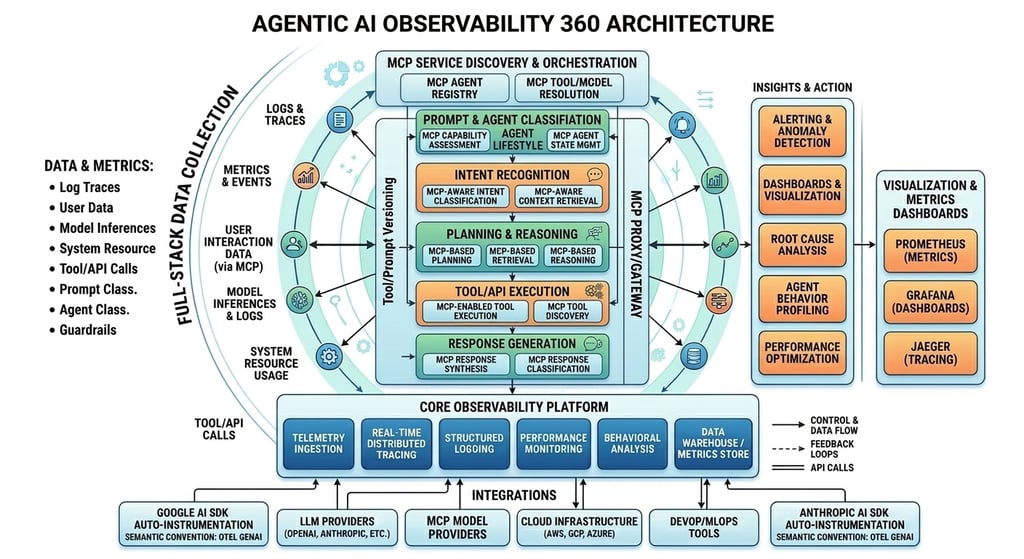
(Note: This image features an architecture diagram at the top labelled "CORE OBSERVABILITY PLATFORM" with various data ingestion paths, followed by text paragraphs.)
Agents are everywhere in all the phases of SDLC. Apply and force Observability 360
Security : ability to support all agentic ai specific usecases. preventive and detective actions for all security usecases such that access control, data security, governance
Behaviour: analytic of agents and user behaviour
Agent collaboration and tool calling
Agent state - persistence (handle data security )
Resilient and reliable agent
Visibility of invisible workflow
Cost per unit of work
Semantic Conventions (SemConv) for all trace/span
Versioning of tool/model/prompt/agent/access policies
Classification of agents and prompts
1. Orchestration & Framework
Need: There are various agantic ai frameworks available. Carefully analyse the framework and ensure the selected framework supports observability by native.
Recommendation : LangGraph allows you to hook into the compile-time graph step-by-step, making it easy to emit telemetry every time a node (agent) transfers control to another node.
2. The Standardization Engine: Semantic Conventions
The Problem: Fragmented AI tooling forces vendor lock-in (e.g., code instrumented for one platform won't read on another).
Standardization of naming conventions that allows to frameworks agonist distributed tracing of agintic ai flow .
Recommendation : use open telemetry gen ai semantic conventions
3. The Front-End SDK Layer
Instrumentation: These vendor SDKs interact directly with the frontier models. Modern Otel auto-instrumentation libraries plug directly into the Anthropic and Google AI SDKs, automatically extracting attributes like raw prompt strings, stop reasons, and temperature variables without forcing developers to write manual boilerplate wrappers.
Recommendation : Use Otel Auto instrumentation which has natively supported these SDK to extract the LLM specific metric data
4. Gatekeepers: Prompt Classification & Guardrails
Real-time Telemetry: Before an intent ever hits an agent, Prompt Classifiers parse the input to determine vector routing. act as interceptors.
Observability Role: When a guardrail trips, it emits a specific semantic span event (guardrail.blocked). This allows SREs to filter dashboard metrics instantly to see if a drop in user satisfaction is due to an over-aggressive safety policy blocking safe agent behaviour.
Recommendation : Guardrails (like NeMo Guardrails or Llama Guard). Custom build solution for Prompt classification.
Spy agents: build some AI based spy agent which will perform some behavior assessment of agents in real time using the agent produced logs, security events, dynamic prompts, invisible workflow and user input. This helps to identify the anomaly and perform some appropriate action by triggering other agent flow.
5. Storage & Visualization: Prometheus, Jaeger, and Grafana To avoid paying exorbitant commercial vendor costs at high token volumes, a classic, robust open-source telemetry engine is ideal:
Jaeger (or Grafana Tempo): Handles the Distributed Tracing. It maps out the exact execution tree hierarchy. You can visually trace how a single query spawned 3 tool calls and 2 agent handoffs, pinpointing exactly which node caused a latency bottleneck.
Prometheus: Handles the Metrics. It aggregates raw numeric data over time—such as total token spend, cache-read efficiency, guardrail violation counts, and average latency per agent.
Grafana: The single pane of glass. It brings Jaeger traces and Prometheus metrics together onto unified dashboards, allowing operations teams to monitor real-time business costs alongside agent behavioural drift.
Conclusion :
In the series of API first, Design first, Security first approaches now Observability first is also should be mandatory. If the enterprise is start to adopt agentic ai then the setting up and enablement of agentic ai observability 360 degree. ARE (Agent reliability engineering) :start to define and build the ARE specific enterprise grade use cases and standards, specification.